【甘快看】我科研团队推出简牍字符检测与识别大规模数据集
科技日报记者 颉满斌
3月25日,记者从西北师范大学获悉,该校联合甘肃简牍博物馆推出了国际首个面向深度学习任务的简牍字符检测与识别大规模数据集。该数据集名为DeepJiandu数据集,是国际上首个专门用于简牍字符检测与识别的大规模数据集。相关研究成果日前发表在国际期刊《数据科学》上。
记者了解到,DeepJiandu数据集包含7416张图像,共标注99852个字符,涵盖2242个类别,提供了极具挑战性的简牍字符识别任务场景,为简牍数字化保护与学术研究提供了坚实的数据支持。该工作由西北师范大学简牍研究院、甘肃省简牍智能计算与数字人文工程研究中心张强教授团队具体开展,上海中西书局、甘肃文化出版社提供相关数据资源,西南大学参与研究工作。
简牍是中国古代记录历史信息的重要媒介,其历史可追溯至战国、秦、汉、魏晋等时期。然而,简牍材料的脆弱性,以及长期埋藏环境,导致出现字符模糊、字迹缺损、布局复杂等问题,使得人工识别与整理极为困难。现有的文献数字化技术虽在甲骨文、蒙文手写体、巴厘岛棕榈叶手稿等领域取得突破,但在简牍字符识别方面仍缺乏高质量的数据集,制约了深度学习在该领域的应用。
DeepJiandu数据集的构建正是为了解决这一问题。数据集覆盖2242种字符类别,由简牍学专家与计算机团队联合标注,确保高水平的释读准确性和机器可读性。此外,数据集的设计考虑到简牍中字符的残损、异形字、多种布局等复杂场景,具备良好的模型泛化能力与适应性,对推动人工智能在古文字领域的应用具有重要意义。

DeepJiandu数据集图像示例
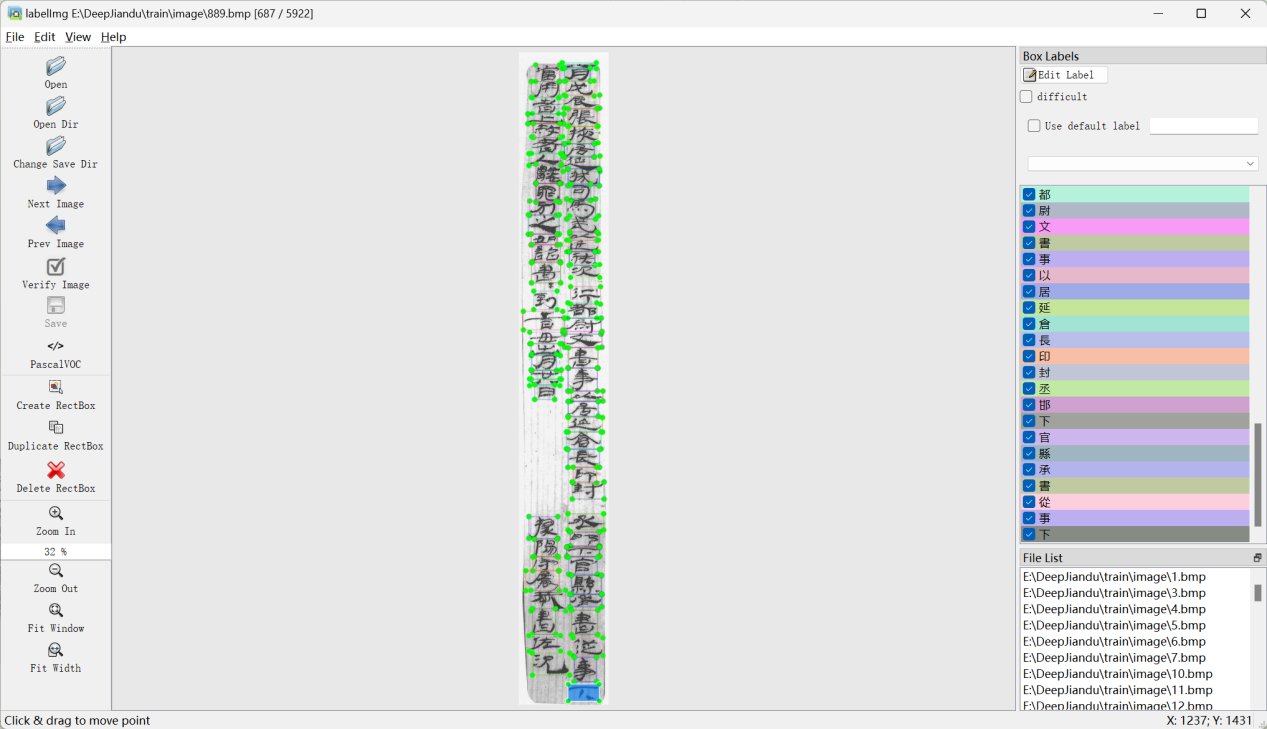
DeepJiandu数据集的字符标注示例,标注框标明了字符的位置和类别
研究团队在DeepJiandu数据集上测试了多种主流字符检测与识别模型。实验结果表明,该数据集能够有效支持字符检测与识别任务,现有模型在该任务上的表现仍有优化空间,特别是在面对字符模糊、残缺、长尾分布等挑战时,DeepJiandu数据集能够有效推动相关研究的发展。
张强介绍,DeepJiandu数据集的发布填补了历史文献数字化与人工智能结合的空白,为简牍整理与自动识别提供了重要支持。该数据集不仅能够提升考古学者对简牍文献的解读效率,还为历史文献OCR技术的突破提供了宝贵的数据资源。此外,结合计算机视觉与历史语言学,DeepJiandu数据集还将推动文博机构的数字化转型,为多模态文化遗产保护提供新的技术路径。
张强表示,未来,团队将继续优化数据集,为简牍智能计算研究提供更好的支撑。团队还在积极开展简牍图像融合、残断简缀合、书写风格识别和简牍大模型等研究,进一步丰富简牍智能内容,走出一条“冷门不冷、数智加热”的人工智能赋能冷门绝学研究新路子。
(受访者供图)

- 2025-03-27【甘快看】敦煌学研究的重要文献——评《敦煌碑铭赞辑释(增订本)》
- 2025-03-27【甘快看】习近平总书记关切事|兴水利民谱新篇
- 2025-03-26【甘快看】高质量发展看中国|甘肃庆阳:县域多元竞相发展 6县进入百亿元行列
- 2025-03-26【甘快看·锲而不舍落实中央八项规定精神】各地推动学习教育有序有效开展


 西北角
西北角 中国甘肃网微信
中国甘肃网微信 微博甘肃
微博甘肃 学习强国
学习强国 今日头条号
今日头条号






